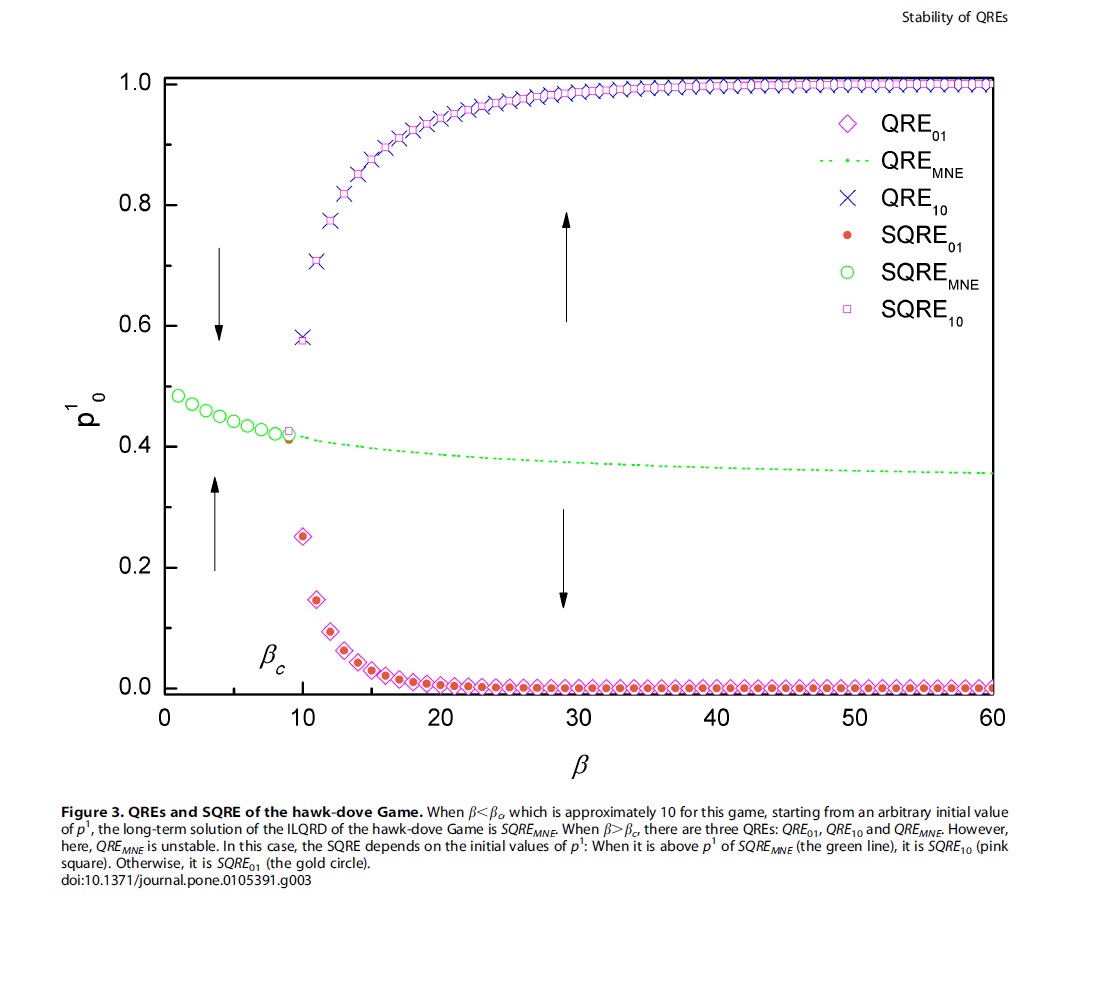
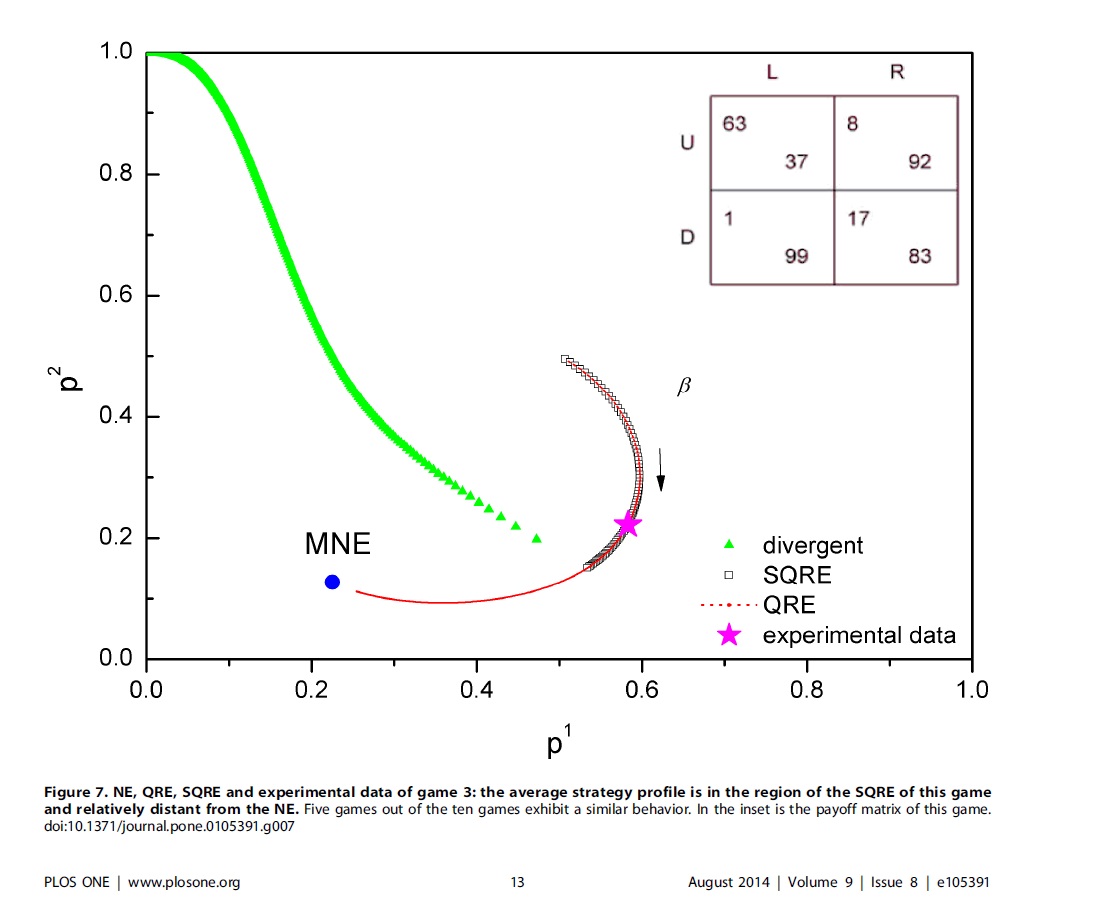
在这个工作中,我们把有限理性的一种描述——静态随机反应均衡(QRE),也就是决策者按照Boltzmann分布来选择好的策略而不是只选择最好的——推广到了一个动态迭代过程的描述,并且讨论了在这个动态模型下的均衡解的稳定性。我们发现,与演化博弈的思路类似,我们的动力学过程也可以把原来静态的均衡解区分成稳定的和不稳定的。其中稳定均衡解的含义就是既是原来的静态解又是现在我们的动态方程的长时解——从某些初始条件开始 演化,最终到达的状态。因此,首先这个区分可以用来做均衡的精炼。其次,我们认为这个按照一定的概率选择好的策略而不是仅仅选择最好的策略的描述 方法,甚至在将来的能够解释实验的更完整的博弈理论里面,也会是有地位的。除了这些理论工作,我们还把我们的均衡解和其他人的实验结果做了初步的 比较。我们发现,在有的博弈中,实验结果确实更加接近我们的均衡解,而不是非均衡解。更明确的结论还有待于进一步的实验与理论的比较。
研究成果:Stability of Mixed-Strategy-Based Iterative Logit Quantal Response Dynamics in Game Theory, Qian Zhuang, Zengru Di, Jinshan Wu, Published: August 26, 2014DOI: 10.1371/journal.pone.0105391

全文链接:http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0105391
邮箱:sss@bnu.edu.cn 邮编:100875 地址:北京市海淀区新街口外大街19号 学院联系电话:(010)58807880
bat·365(中文)官方网站(官方)EuroCup/下单平台 版权所有

院微信公众号

BNU系统学工